
Introduction
A photo-mosaic is an image that is composed of many smaller images. Creating photo-mosaics is extremely difficult by hand, yet relativity simple to do computationally. The algorithm to generate a photo-mosaic can be described as follows:
- Pick a target image and split it into a grid. This image will act as the base for the mosaic to resemble.
- Find a large number of other images. These will become the palette images that will make up the mosaic.
- For each grid square of the target image, find the 'closest' matching palette image and replace the pixels in that grid square with the palette image, resized to fit. We'll discuss what is meant by closest later in the article.
The intent of this project is to experiment with the application of photo-mosaic tiling for the generation of video; where each frame from the video is a photo-mosaic. It is not necessary to write a distributed solution for the generation of single photo-mosaics because it is computationally inexpensive. However, when the desire is to generate high resolution photo-mosaics for 30 frames per second digital video, a distributed solution becomes advantageous.
Project Goals
The goal of the project was to build a system of generating photo-mosaics that is efficient enough to feasibly convert all frames of a video into mosaics. Because each frame can be mosaic'd independently of other frames, a distributed system is a natural solution. In addition to creating a way to distribute the processing of photo-mosaics, we also wanted to experiment with ways of gathering and processing the images to make content that is interesting when converted to video-mosaic.
Design and Implementation
Creating a video-mosaic can be broken down into the following steps:
- Explode target video into its individual frames.
- Recreate each frame as a mosaic of palette images.
- Compile all mosaic’d frames back into digital video.
For steps 1 and 3, we found it effective to manually extract and recompile image sequences from the video files using QuickTime Pro. This was a simple step that would have been difficult to do programmatically because it would have involved cumbersome video programming APIs. Our content workflow consisted of first filming a target video and palette video and extracting both to image sequences using QuickTime. The second step was to use a simple Python script to size down the palette images to their intended size for the output video. This step significantly reduces our file size and eliminates the need to resize palette photos during the generation processes.
As mentioned before, step 2 is the more interesting step and hence is what the following discussion will be limited to. It is important to note that the problem is highly parallelizable because our approach doesn’t consider any data dependency between any of the frames. Therefore, the work of mosaic creation can be spread across an arbitrary number of machines.
The problem of finding palette photos that are 'closest' to the region of the target being replaced was mentioned earlier. Given a target image and a set of palette images, how can we best create a mosaic of the target using the palette? This discussion considers two dimensions for the word ‘best’: quality and efficiency.
Quality
The goal is to create a mosaic that resembles the given target image as much as possible using some fixed palette. The two parameters to this process are mosaic resolution and the replacement algorithm.
Mosaic resolution is the number of palette images we use to create a particular mosaic; a large value is good because it yields mosaics that look more like the target frame, and a small value is good because it makes it easier to see the individual palette images that make up the mosaic. A resolution of 40x40 would mean each frame is made up of 40*40 = 1600 palette photos, each of dimension 1920/40 x 1080/40 = 48x27 pixels, because our target images are 1920x1080 resolution (standard HD 1080p format video frames).



The other parameter, the replacement algorithm, is critical for finding the best matching palette image to replace a particular section of the target image. All comparisons were based on computing the mean color value for images and storing them as three dimensional vectors [mean(Red), mean(Green), mean(Blue)]. The distance metric used to compare the vectors was Euclidean distance: sqrt( (R1-R2)^2 + (G1-G2)^2 + (B1-B2)^2 ). The simplest approach to generating the mosaic is for each target sub image, find the closest palette image to it. An extension we implemented was the ability to 'drill-down' into palette images by computing multiple vectors for each palette image. This is done by slicing each palette image into sub images itself and computing the vectors for those sub images. This still allows for equivalent Euclidean distance calculations, except now in more dimensions. For example, if we drilled down into quadrants (2 by 2 sub images), then our distance calculation would be in 3*4 = 12 space. The vector would appear as [R1, G1, B1, R2...,G4, B4]. By doing this, variations within the palette images are not averaged out, and aid in detections of things such as edges and color gradients.

Efficiency
An efficient implementation of the replacement algorithm (described above) is critical for high-quality video-mosaics to be produced. The reason for this is that one wants a large palette for replacing target image sections; it's important to be able to find matches for RGB values across the color spectrum.
The naive replacement algorithm would say for every section of the target image, loop through all palette images to find the one with the lowest Euclidean distance to it. Unfortunately this is a S*N step operation where S is the number of sections in the target image and N is the number of palette images. However, our implementation uses nearest neighbor search on a kd-tree containing all the palette images to find a best match. With a small overhead to construct the kd-tree, and a reduction to log(N) steps for finding the best replacement image, our implementation now supports much larger palettes. For example, with N = 80,000 and S = 1600, the naive approach takes 128,000,000 steps while our approach takes about 26,000. And because nearest neighbor search also uses Euclidean distance as a distance metric, its output is the same as the naive approach.
Performance
We measured the performance of our system on a single processor, and then made postulations as to its performance on a cluster. Because the algorithm is identical on a cluster as on a single processor machine, we can effectively measure performance with just a single machine.
Single Processor
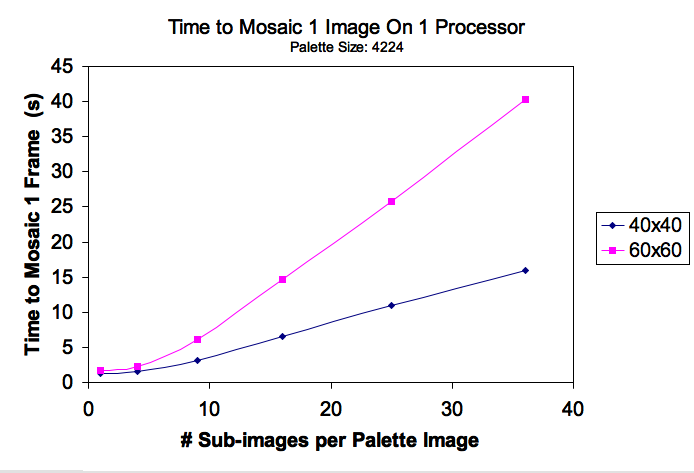
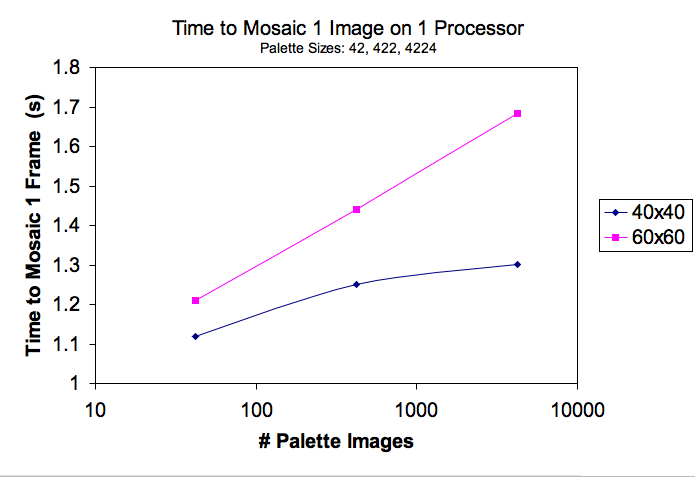
In reference to figure one, it is shown that as the number of palette images increases the algorithm experiences logarithmic slow down. Figure two shows that drilling down into palette images incurs a linear slow down in efficiency.
Ad-hoc Cluster
For testing and portability, we designed a system to distribute computation across an arbitrary number of generic linux machines. Generic meaning no specific system or network architecture. This system is driven by a shell script over SSH. The ad-hoc cluster we ran our system on was composed of 16 commodity machines at the University of Washington. As anticipated, the performance speedup from a single processor was linear with the number of machines in this cluster.
Hadoop Cluster
Running our system on Hadoop causes a large initial overhead for copying all palette and target images to each mapper local box. This overhead is necessary because Java's imaging libraries require files to be read and written to a local filesystem instead of Hadoop's DFS, and can actually dominate the time it takes to create the mosaics. This is because copying a large number of small files in DFS is painfully slow. Once all files are copied however, we once again obtain a linear speedup from a single processor with the number of nodes in the cluster for creating mosaics.
The implementation of the MapReduce system involves a driver that distributes the frames to and palette images to each mapper. The Mapper then builds the kd-tree from the palette images and generates the mosaics from the target images and writes it out to a common directory where all the output frames will be placed.
Project Outcome
A few of the final videos can be viewed below. They are HD 1080p quicktime mov format.
The Quad (grid size: 40x40. 6x6 palette drill down).
The Quad (grid size: 60x60. 6x6 palette drill down).
Face Experiment (grid size: 40x40. 6x6 palette drill down).
Conclusions
The VideoMosaic project resulted in an exciting technology for creating a unique and engaging video effect. By distributing the computation, neither the length or resolution of the video proved to be major limitations in production of VideoMosaics. Generating content that was conducive to the video mosaic format proved to be the most difficult factor. A lot of thought and effective preprocessing is necessary to effectively apply the effect. The first example above in the quad appears to be pixelated rather than composed of smaller images. This is because the palette photos were not recognizable in there smaller form. However, the second video is more successful because we as humans are more attuned to facial recognition. This allows both the large and small images to be recognized, which is complimentary to the effect.
Looking Forward
Programmatic Extension
In the next iteration of the VideoMosaic project I would like to experiment with including inter-frame dependency for determined chunks of frames (for example, each contiguous set of 15 frames would be processed together). This would allow for advancement in eliminating the flickering images that appear in the current videos.
Artistic Applications
There are a number of direction in which I would like to take this project. The first is further exploring content. I would like to create a more art directed VideoMosaic sequence. The effect would not necessarily be stand alone, and may be useful in a title sequence for a larger work, perhaps in combination with blue screen compositing where not the entire frame is composed of mosaiced effect, but just one character for example.
Live Video Installation
The most exciting idea to emerge from the VideoMosaics project is a plan for a live video installation. By implementing the project in an environment more suitable for image manipulation and on a multi processor machine, it would be conceivable to achieve real-time photomosaic generations as fast as a few frames per second. This opens up the possibility of rendering real time video feed as VideoMosaic. The gallery implementation of this would involve a camera capturing viewers and rendering their image as mosaics composed of images of themselves and previous viewers. The longer the system was active, the more dynamic the content would become as viewers interacted with the camera. There is also a poetic elegance in the idea of your identity being composed of that of others; as our individuality is ultimately a collection of interpersonal dependencies.
Source Code
Below is a link to download the source code. This includes both a local machine running client, a set of shell scripts to run on the 'ad-hoc' cluster, and the MapReduce classes for Hadoop. Instructions are included in the README file
Download the source.